Recently we did a blockchain experiment for VDAB (public employment service of Flanders) together with GO! (community education institution in Flanders) with Hyperledger Fabric, where competences are stored on a blockchain. One of the issues that needed to be tackled when working with multiple parties, was the data-standardisation problem. The outcome regarding this topic is covered in this post.
Although Hyperledger Fabric is private/permissioned blockchain technology, the key points addressed below are also applicable to public blockchains.
The Problem
To explain why there is a problem with data-standardisation when working with blockchain technology, let’s look what blockchain actually brings to the party.
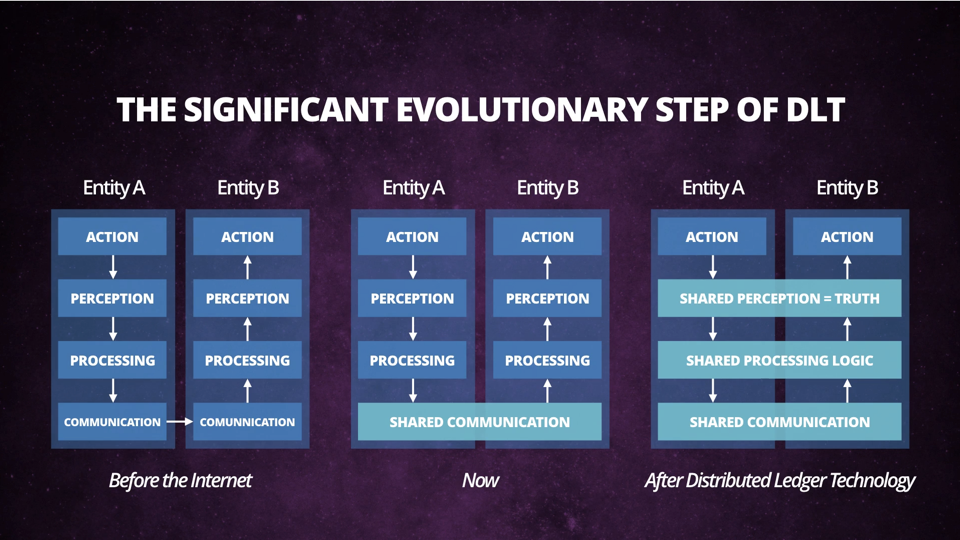
The new shared layers of ‘shared perception’ and ‘shared processing logic’ impose new opportunities as well as problems to solve. Around the ‘shared communication’ layer that we already use today, we have created interfaces/abstractions — like API’s — to be able to communicate in a more structured way. Likewise, there needs to be thought about abstractions — and governance of these abstractions — for the new shared layers of ‘shared processing logic’ and ‘shared data’.
Once you talk about ‘shared data’ across multiple parties, you inevitably talk about standards regarding the data. All participating parties must agree on standards regarding the data before using the blockchain, since written transactions on a blockchain are immutable. In the case of storing competences on-chain, the questions become: “How do we define a competence on the blockchain?” and “Which competence-standard are we going to use?”
Duct tape fix
One way to approach this problem as a consortium member, is as follows:
Once the shared standard is chosen, both entities need to modify their data according to the agreed standard so they can interact with the blockchain.
This could work when you have only 2 parties.
But what if a third party wants to join?
Maybe this party requires the standard to be changed when he wants to integrate with both other parties.
Then what happens with the ‘old’ assets stored on-chain?
Can we do an internal data-migration with data already on-chain when the one schema changes? Then who would be responsible for this migration? What if your one chosen standard becomes outdated?

This simply wouldn’t work. What’s worse, by choosing standards and sticking to them, you are scaring off other potential partners who would want to join this consortium, since it would require them to comply to yet another standard that some other consortium already has chosen. Since the whole point of the idea of storing data on-chain is to ‘write once, re-use everywhere’, this isn’t a viable approach. Especially in cases where a lot of schemas are being used (like diploma’s and certification for example)
A Solution
Another way to look at this standardisation-problem is a follows
“It is not the strongest of the species that survives, nor the most intelligent that survives. It is the one that is most adaptable to change.” — not really Charles Darwin, but still applicable.
The problem was already obvious from the start of the experiment. Choosing 1 standard isn’t really future-proof when considering you want to include more partners in the long run.
During an initial workshop, a lot of possibilities where put forward and discussed. To summarise the ideation outcome, these where some ideas that floated around, written down chronologically:
- What if we DON’T use a standard?
- What if we allowed ALL standards?
- What if you could bring your own standard?
Let me walk you through the pro’s and con’s of each idea.
What if we don’t use a standard?
If you don’t use standards, then you simply cannot do (manual) integration anymore. This way, it will be easy for newcomers to push their data on-chain. However, it will become increasingly hard, to interpret the data from different entities. But with the recent advancements in AI, maybe AI could help in parsing these different blobs of data so integration would be done by AI instead of people?
Of course AI isn’t all powerful. You need to bootstrap algorithms and point it in the right direction by supplying meaningful datasets. That’s how we came to discuss this follow-up question:
What if we allowed all standards?
Okay, so we decide that there needs to be some guidance for AI to be able to parse data and come to conclusions. So would it be enough to post metadata along with your actual data, like schemas/standards you used? Just like XSD for XML, or JSON Schema for JSON?
Again, allowing all data formats, even with schemas along, would still be too difficult for AI to begin with (at least for now). And AI aside, not everyone is using it. It should still be possible to integrate manually. To be able to do that, there needs to be limitations on the standards that can be proposed. And so we came to the following idea.
What if you could Bring-Your-Own-Standard?
What if you just start out with a specific set of allowed data-standards, proposed by a consortium of partners. Whenever a competence is pushed to the blockchain, it should be following one of the accepted standards. Doesn’t matter which one, as long as it complies to one. Your smart contract is your safeguard to allow only competences that follow one of the accepted standards: this is where your schemas live.
Consider the example below, where GO! and VDAB both use there own standards (‘learning objective’ and ‘competence’ respectively). By allowing everyone to use the standard they are already using internally, nobody needs to bother with integration-problems. Meaning: nobody needs to integrate between their own local standard and a single on-chain standard. Thereby minimising the effort needed for a new player to enter the consortium with his own standard. This results in benefits for all, not only (1) for all partners of the consortium (more members = more weight behind on-chain data), but (2) also for the individual who’s competences are being stored on the blockchain (more members = more entrypoints to add/read data to/from my profile, therefore more applications which can use my on-chain data).
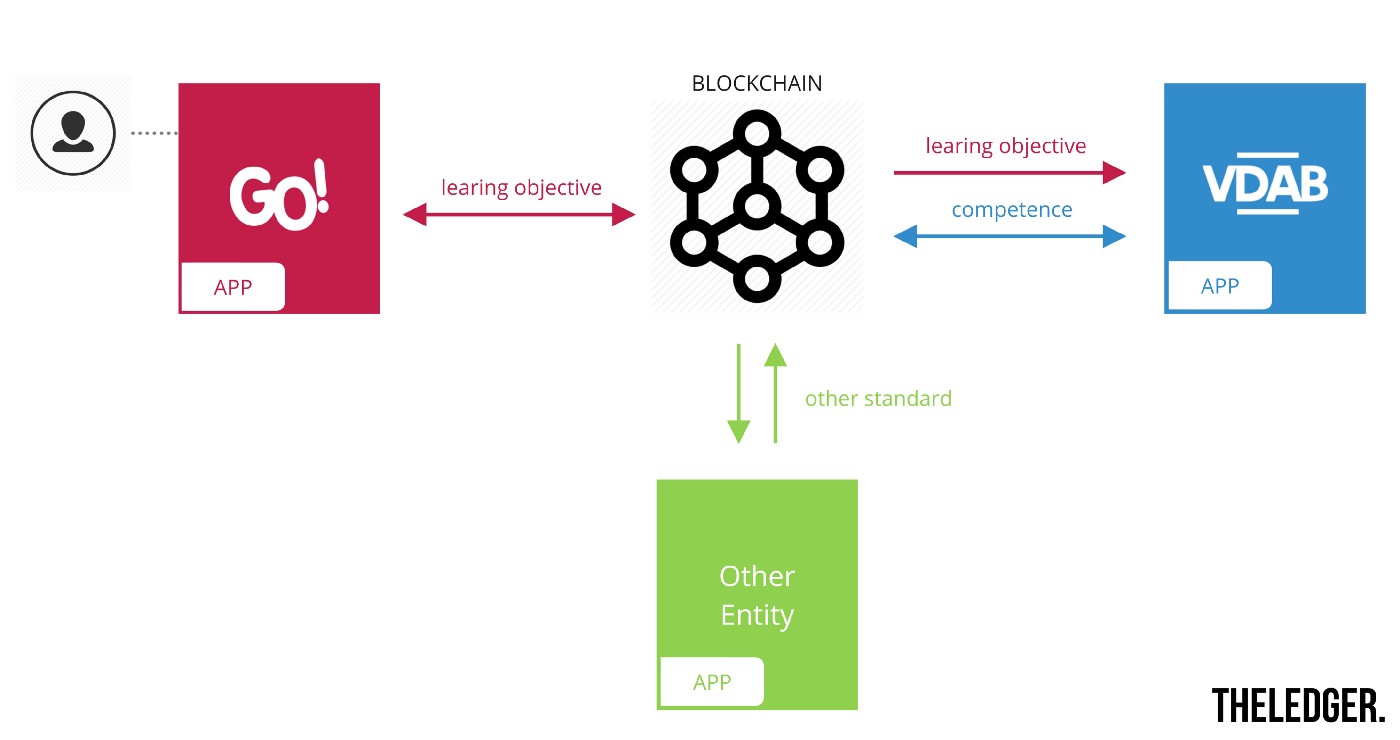
It goes without saying that the user who gets competences assigned through these applications, remains in complete control over his own data. Even when new partners join the consortium. Access control is safeguarded by the smart contract layer itself. Who gets access to certain parts of the user’s data is completely up to the user (data-owner) himself. The fact that this data, who gets assigned to this user, follows different standards, shouldn’t matter.
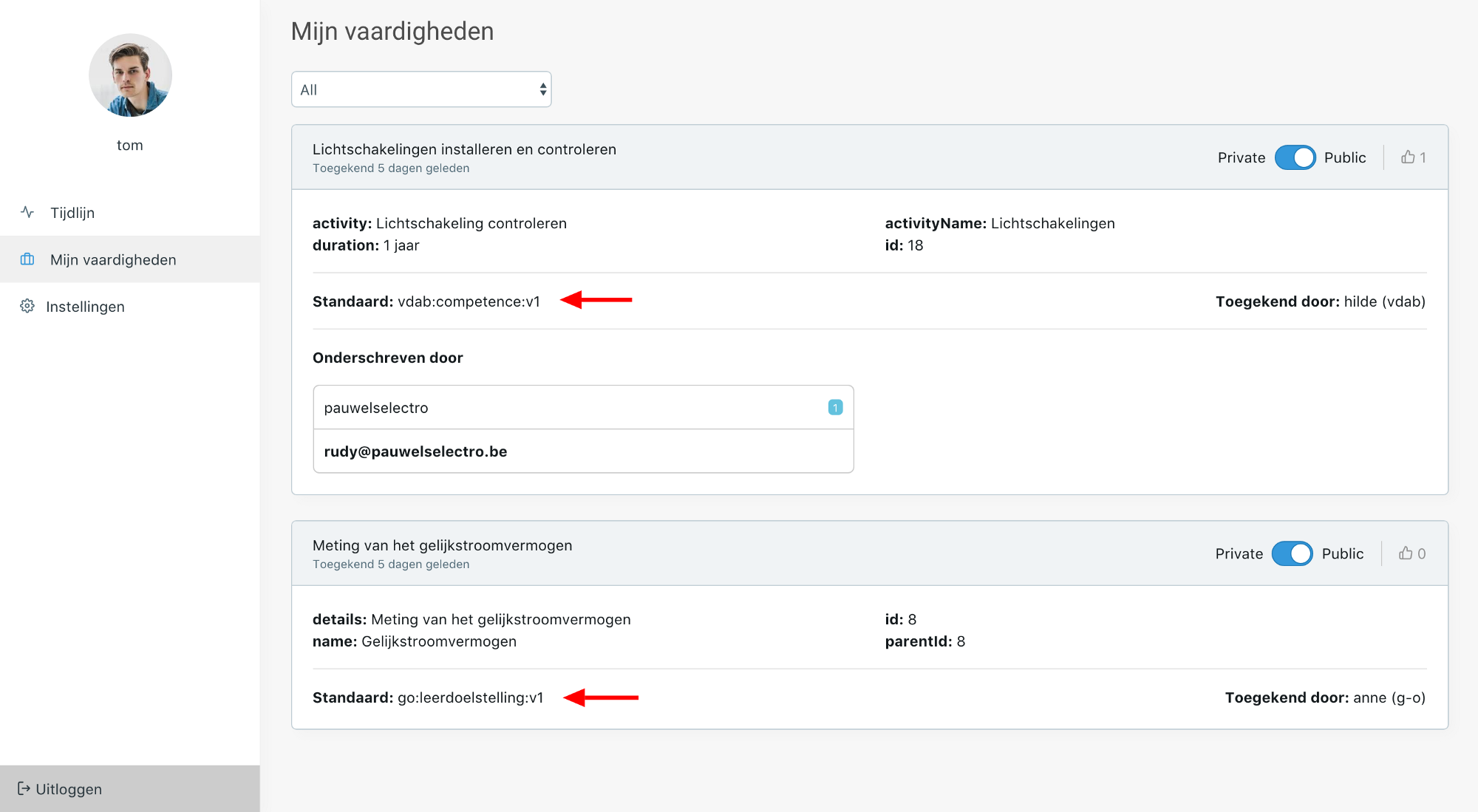
Given the image above, the ‘VDAB-app’ can show the user’s data, even if they follow different standards. Below is a screenshot of our front-end displaying these results, while the data is fetched from HyperLedger Fabric. The standards each have their own JSON-LD schema defined on-chain.
Concerns
We skipped pretty quickly over some major issues in dealing with standards this way. Namely, integration between standards who live on-chain, internal data-migration, and GDPR when dealing with personal information.
Integration
By allowing multiple data-standards for your assets (e.g. competences in our use case) on-chain, you postpone the problem of linking/integrating this data. After all, how can you (or your system) draw conclusions when there are no dependencies between these different types of assets? To get around this issue, consider the picture below.
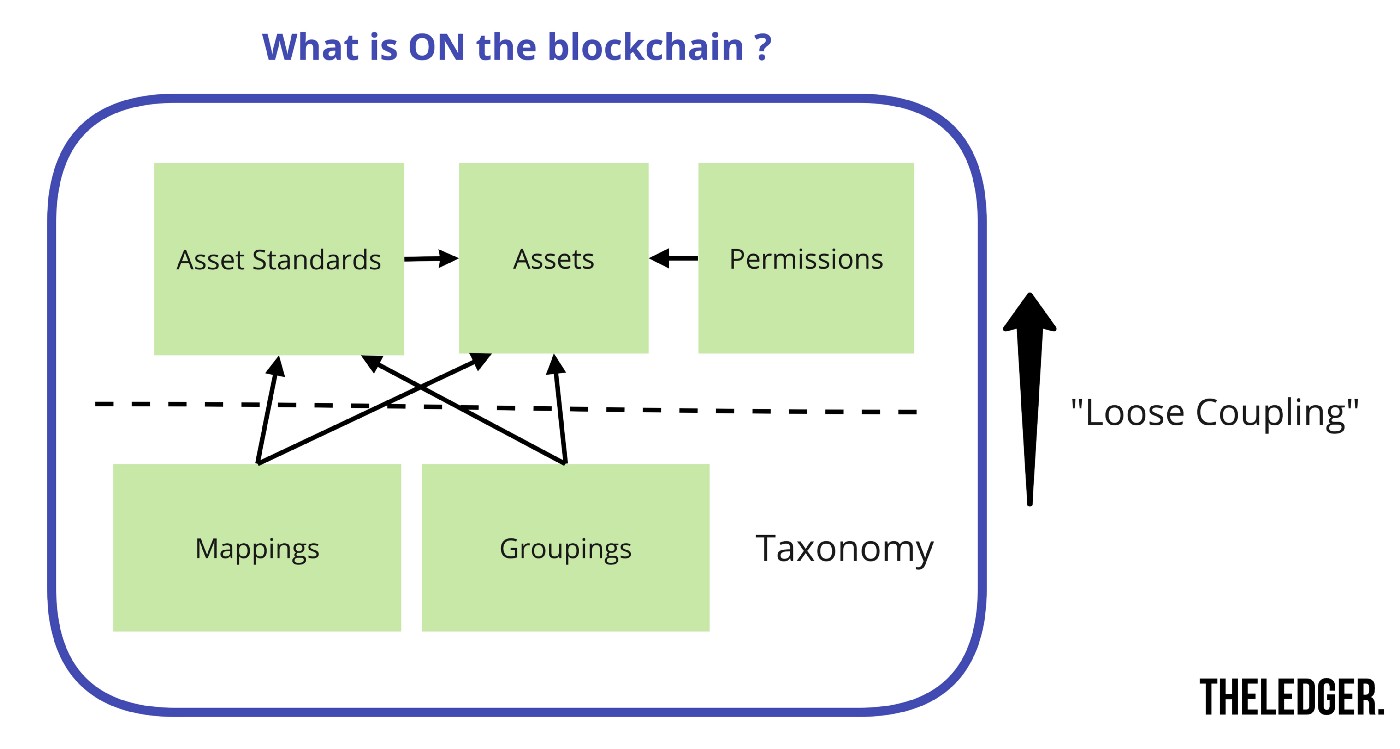
All ‘assets’ and their ‘asset standards’ live independently of each other. There is no hard link between different standards stored in the standard or assets themselves. But that doesn’t mean you can’t link data by defining rules (‘mappings’ in the picture) who link different assets to each other. We create a loose coupling by splitting taxonomy from the actual data. An example of such a rule could be “If asset A from standard B has been given to a user, then he has the equivalent of asset C from standard D”. Each consortium player can add and retract their own taxonomy rules, like mappings and groupings. These do not even need to be on-chain, but by doing so, they become more ‘official’ and transparent.
The point is: adding and retracting rules have no effect on the assets themselves. Therefore, the user is never hindered by these actions: his assets stay the same.
Internal data-migration
Schemas change. When you are dealing with multiple schemas on-chain, you’ll need a way to let all of them change themselves. In figure A above, you can see the naming convention of the schema’s we used. For example: vdab:competence:v1 or go:learningobjective:v1
What if VDAB wants to upgrade their internal standard? From vdab:competence:v1 to vdab:competence:v2 for example. An option could be to add an upgrade function in the smart contract. In pseudocode:
function UpgradeAllData(standardVersion SA, standardVersion SB) {
if (mappingRules exist to upgrade SA to SB) {
// store new version based on these mappingRules
// and remove data of old version
} else {
// throw error
}
}
Here we see an another advantage of storing mapping rules on-chain. It can also help in upgrading existing standards to new versions. The transaction on the blockchain, originating from this function, will state that all data from the previous version is removed and from the new version is added. Resulting in a new world state (when adding all past transactions) where no more data of version SA exist, but instead became data of version SB.
Data regulations
When dealing with data of a personal nature, you’ll need to consider regulations regarding personal information. I’ve talked about GDPR and blockchain in a previous post, so I’m just going to propose a possible solution here. The ‘assets’ part in the picture above doesn’t need to be the actual data about the asset. It can contain a link to an off-chain storage where the actual asset is stored, along with the hash of the data and access keys to be able to fetch this data from off-chain storage.
Governance
We haven’t covered the governance of the bring-your-own-standard principle. Who decides which which standards are being accepted? Who controls this layer? There are multiple ways to solve this problem. Also, depending if you use a private/permissioned blockchain or an open blockchain technology, approaches can differ.
Private/permissioned blockchain governance
In the case of a private/permissioned blockchain like Hyperledger Fabric, one could for example take decisions in a closed meeting with all consortium members where a vote takes place to add a new accepted standard to the blockchain. After a decision has been made, new ‘chaincode’ (smart contract in Fabric) is pushed to the blockchain with the accepted standard included.
Or, the voting can be done on-chain as well were all the procedure is executed by another smart contract on the same blockchain. Voting rights could for example be assigned based on the number of nodes (‘peers’ in Fabric) a consortium member has. Lots of possibilities here.
Curated governance
Another interesting approach is curated governance. This can be used both in closed and open systems. In this type of governance, voting is done by proof-of-stake consensus. For example, in the case of voting for new data-standards, each participant stakes his vote with crypto. The standard can then be accepted or rejected based on the outcome of the stakes. A participant can be a consortium member in the case of private blockchains, or any individual in the case of public blockchains.
As you can see, how governance is done can widely differ by use case and by preference.
Final remarks
The concept of bring-your-own-standard is only one way to approach the data-standardisation problem, but others exists as well. It comes in handy when assets themselves are stored on the blockchain. When using the blockchain purely as a claims verification principle, it can be sufficient to only store fingerprints on-chain. The standardisation problem then becomes less of an issue.
Thanks for reading!
Last modified on 2018-01-31